E note
【E CROSS TALK REPORTS vol.22】マーケティングのためのデータ活用講座
〜インサイトを引き出し、戦略を磨く〜
こんにちは!
今回は4月17日のワークショップ「【E CROSS TALK vol.22】マーケティングのためのデータ活用講座〜インサイトを引き出し、戦略を磨く〜」の内容を抜粋してお届けします。
データサイエンティストの普及啓発につながる支援や活動を行う、株式会社Rejouiの菅 由紀子氏をお招きし「マーケターのためのデータ利用・活用」をテーマにワークショップを開催。
実際の事例を交えながら、マーケティング領域で行われるデータの利活用やその重要性についてお話しいただきました!
また講座内では演習を実施。データの読み解き方や仮説立案方法など、実践的な学びも得られたワークショップでした。
今回は大充実のワークショップの内容を一部抜粋して紹介します。
講師プロフィール

菅 由紀子(Yukiko Kan)
代表取締役
データサイエンティスト協会 スキル定義委員
広島大学 客員教授
株式会社サイバーエージェント、株式会社ALBERTを経て、2016年に株式会社Rejouiを創立。実務家データサイエンティストとして分析プロジェクトを指揮するほか、多くのセミナー登壇や教育カリキュラムの開発など活動は多岐にわたる。2021年には、米国スタンフォード大学ICME発のデータサイエンス人材育成シンポジウム 『WiDS』 公式アンバサダーとしての活動が評価を受け、日本統計学会統計教育賞を受賞。現在は広島大学の客員教授としても活躍中。
イントロダクション
まずは菅さんに登壇いただき、自己紹介やご自身の経歴、会社に関してご紹介いただきました。自己紹介も数字を交えた具体性たっぷりのお話が印象的!
また、みなさんからの自己紹介や質問にもお答えいただきました。

本題に入る前に、まずはデータサイエンスをやる・やらないに関わらず「データは大事」という話をしますね。
2023年7月のニュースで「マイナンバーカードの情報流出があり自主返納が激増している」というものがありました。
この「激増」という根拠として挙げられていたのが、返納件数。2023年4月に返納が10件なのに対し、5月に個人情報流出の情報が出てから318件になったそうです。これだけを見ると増えたように感じますよね。ところが、マイナンバーカードの総発行枚数は約8000万枚。割合でいえばごくごくごくごくわずかなんです。激増とは言い難いですよね。
このように数字自体は間違っていなくても、書き方やグラフの見せ方によって、印象は大きく左右されてしまいます。だからこそデータを正しく読まなければいけないんです!
どうしてマーケティングの実践にデータが必要なのか
ここからは、どうしてマーケティングの実践にデータが必要なのかという話をしていきます。
みなさんはYouTubeなどを見ている時に「過去にこの商品の広告を見たことがありますか?」というアンケートが流れてきたことはありませんか?
このようなアンケートにおいて、買った方100人に聞いたら51%が「見た」と答え、買っていない方100人に聞いたら49%が「見た」と答えたとします。確かに数字としては商品購入者の方がポイントは高いですよね。でも「ポイント高いので、広告出稿をやります!」というのは、ちょっとやめたほうがいいかもしれません……
これがもし、答えている人が600人ずつで51%と49%の差だったらどうでしょうか?
同じ51%と49%でも、100人の時では2人の差です。明確に「広告が購入につながっている」とは言い難いと思いませんか。一方600人の時では……迷いますよね。この場合は「統計的な有意差」を見て判断しなくてはいけないかもしれません。
この例からも、いかにデータを正しく集め、理解しなくてはいけないかがわかりますよね。
ただ「本当にこの広告を見て買ったのか?」「売れているから買っただけなのか?」といった物事の背景も確認する必要はあります。そのうえで、判断に迷うようなデータの場合、現在だと生成AIに聞くと答えを導き出してくれることもあります。
マーケティング領域におけるデータ活用のお話
ここからは「マーケティング領域におけるデータ活用」のお話に入っていきたいと思います。
20年ほど前に行われていたマーケティングの手法は、「男性か女性か」「何歳の方か」などによってURLが違うメール配信を行うものでした。性別、居住地、未婚既婚、お子さんがいるかどうかのような「属性情報」をアンケートで答えてもらい、それに基づいてメールを送っていたんです。
その後、インターネットの普及に伴って「ビッグデータ時代」に突入します。顧客の閲覧したもの・購入したものをデータで取得することができるので、それらを活用してリアルタイムに「お客様一人ひとり、すべての対象者に価値のあるものを届けましょう」という「1to1」の考えにシフトしていったんです。
対象者へ個別に、もの・こと・サービスそしてタイミングを最適化して届けるというのが2005年ぐらいからはじまりました。また、データ解析の人数が大幅にアップしたのもこの頃です。
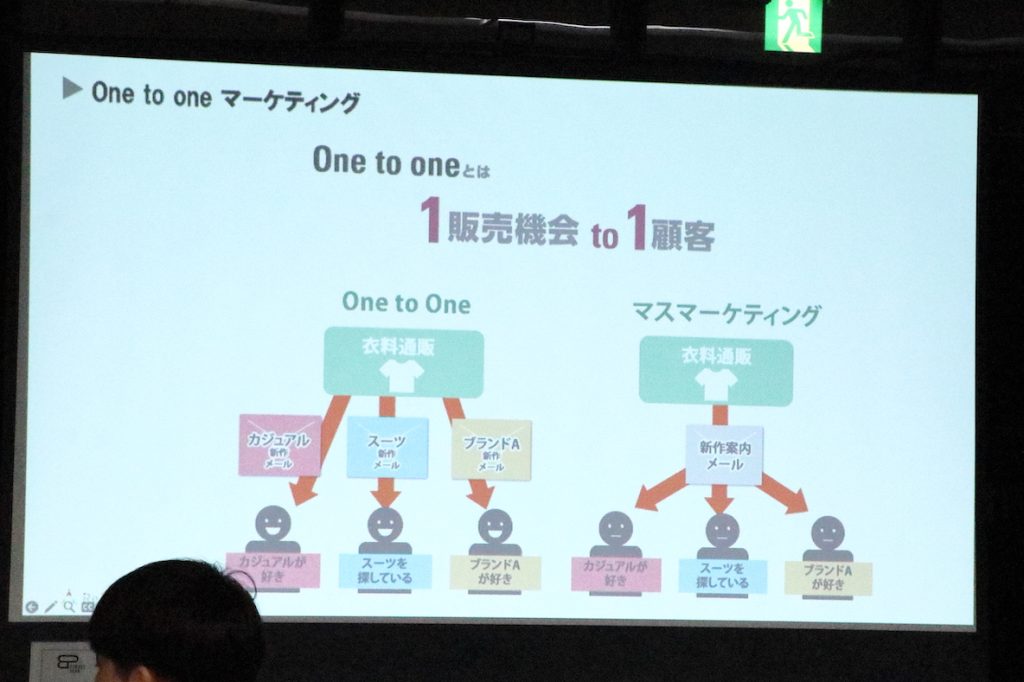
「1to1」は1回の販売チャンスにおいて、1人の顧客に対し個別に最適化して育てていくという考え方です。
それまで中心だったのは「マスマーケティング」。新聞やテレビCMのように、受け取る方全員へ同じ情報を届けるものでした。「1to1」はマスマーケティングとは異なり、現代のようなさまざまな生活スタイルに合わせて、一人ひとりに最適化した情報を届ける手法に変わってきたことは、みなさんもイメージできると思います。
マーケティングに使われるデータにはどんなものがあるのか?
では顧客を理解するデータには、どのようなものがあるでしょうか。

年齢・居住地・未婚既婚・子どもの有無・持ち家か賃貸かなどのデータは「属性データ」といいます。これによるセグメントは崩壊しつつあるのですが、この違いが明らかにマーケティングアプローチの違いにつながる例は現在でもあります。
「心理的データ」は、価値観やライフスタイルに関するデータです。たとえばサステナブルなものが好きとか、コスパ重視など。このデータは観測するのが難しいといわれていて、同じ人物であっても変化するものですよね。このデータから何を買うのかを精度高く予測するのは非常に難しいんです。
「行動履歴データ」は検索履歴や購入履歴などのデータのこと。あるモノやコトを検索すると、それに関する広告ばかり表示されますよね。これは行動履歴データを使っているからです。何かを見た・読んだなどのデータを元に、一人ひとりに最適化するために使われています。
これに基づいて「あなたにおすすめ」や「これを買った人はこれも買っています」などを表示させる技術は「レコメンド」といわれています。
たとえば私は、Googleに「30代男性」だと思われているようで、マッチングアプリの広告やヒゲ脱毛なんかの広告が出てきます(笑)。これは普段、検索で論文を調べたりビジネスセミナーについて調べたりしているので、AIが30代の男性と同じ傾向にあると判断して広告が出ているんです。
もう一つ大事なデータとして、「コミュニケーションデータ」というものがあります。たとえばコールセンターなどに問い合わせると「品質向上のため録音させていただきます」というアナウンスが入りますよね。これは「コミュニケーションデータ」をとっているんです。
問い合わせやクレーム、SNSのやりとりなど「お客様とどんなコミュニケーションをとったか」という部分は、まだあまり活用が進んでいない。でも今後は、AIの登場によって活用されるようになるのではないかと考えられています。

ここで「AI」の話が出てきたので、少し触れておきます。データサイエンスの業界も、他の業界同様にAIの登場によって大きく変化がありました。
AIが登場するまでは、解析のために頑張って数式をつくっていました。これが大体10年くらい前までの話。今はすべてAIによって生成できるため、つくらなくてよくなったんです。
技術も10年ほどで大きく進化しています。
昔のAIは “「札幌」と打ったら「海鮮丼」と返す”というようなものを、人間が指示していました。それが現在では、過去の日本の観光に関する問い合わせについて、すべて学習するというように変わっています。発生確率が高いキーワードの文章を、今の季節に合わせて自動で返してくれるようになったんです。
これ以外にも、生成AIの登場によって「文章の生成ができるからコピーライターがいなくなるかも」「効果的なデザインを生成できるからABテストが不要に」「SNSへの自動投稿」などが可能に。私自身も「サービスや商品の説明文作成」などで活用しています。
AIはマーケティングで活用できますが、循環ができていないとうまくいきません。というのも、マーケティングは「売れる仕組みづくり」であり「顧客を創造すること」です。マーケティングでは「一人ひとりに最適化された情報」を届けることが大事ですが、これはつまり「お客様が興味を持ったか・持っていないか」の情報です。
常に一人ひとりの情報を蓄積し、行動履歴を元に施策を実行。その施策に効果があったか否かもデータとして蓄積していく…という蓄積→分析→実行を循環させて初めて、AIが活用できるんです。
マーケティング領域におけるデータ利活用とは

ここまではマーケティングに使われるデータに、どのような種類があるかを紹介してきました。ここからはデータを、どのように活用していくかについてお話ししていきます。
データを使ったマーケティングにはさまざまな種類がありますが、いずれも「お客さんの未来を予測する」のが目的です。たとえば「菅さんが札幌に次回来る確率は、何日後に何%」というようなことも予測するんです!
これは実際に旅行会社のデータ分析をしていた時「月曜日に予約をする人は、次回予約するのも月曜日」というような解析ができていたので、ある程度は予測できます。
「データを元にどうやって戦略を立てるのか?」というのがデータサイエンティストの仕事であり難しい部分でもあるのですが、今日はみなさんにも体験していただこうと思います。
ここからは「データサイエンティスト」の体験をワークショップで行うことに!
演習1: 化粧品EC事業者の例を用いてデータ解析体験
今日は「化粧品のマーケティング」について体験していただきます。実際に私が取り組んでいるテーマということや、化粧品のマーケティングはものすごく最先端かつ変わらない傾向などもあることから選びました。
課題:健康や美容に関連する企業
ここでは仮に、先端美容やIoTデバイスなどの研究を行っている化粧品メーカーを想定します。
幹細胞美容やスマートミラーなどの研究・開発を行っているメーカーです。化粧品やサプリメントなどを販売しており、メインターゲットはミドル世代の女性。UVケア商品と幹細胞由来の美容液が主力商品です。
数年前に人件費や宣伝費の削減のためTVCM通販をやめ、オンライン通販に舵を切ったという経緯があります。ですがターゲットがシフトしてくれないという課題も抱えています。ただ定期的に購入するお客様も多くおり、定期購入を希望する声も上がっていることから、2021年から化粧品のサブスクサービスを開始しました。
ここからは、上記前提に加えて過去4年の売り上げデータをもとに、分析を行うことになりました。
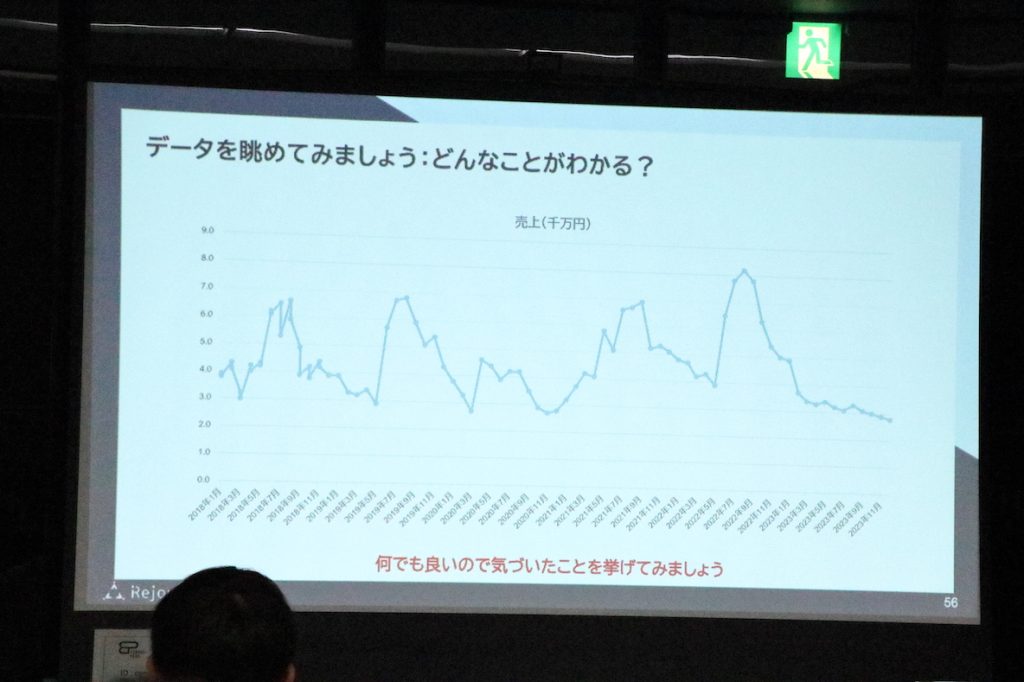

データから未来を見抜くとき、データを見るときのメソッドがあるので紹介します。
データの特徴的な部分を見つける
データのなかで、突出した部分を見てみましょう。高いところだけではなく、低いところを見るのがポイントです。偏っている部分には、必ず何かしら理由があります。
パターンや周期性を見つける
「毎月月初は定期便の申込みが増える」「これを買ったらこれも買われる」などが、パターンや周期性です。
たとえば季節や曜日などは、基本情報として入ってきます。さらに、起こることがわかっている行事・イベント、札幌でいえば雪まつりなどは「すでに起こった未来」といわれ、データを読み込む上で重要です。これらを知っておくと、パターンに気が付きやすくなりますよ。
グラフに線を引く
実はグラフに線を引くだけで、分析がしやすくなります。1年や半年などの周期で線を引いてみましょう。
ここで忘れてはいけないのが、データを見るだけで終わるのではなく「仮説を立てる」こと。「これが起きたのは〇〇が原因かな?」と考えることが仮説です。
みなさんにお渡ししたデータでは「毎年夏の売り上げが高い」というパターンがあります。なぜか?これは夏に売れる商品があるからと仮説が立てられます。仮説を立てることによって、確かめるために「売上の商品の内訳を調べよう」となりますよね。
この仮説を検証するのが、データサイエンティストの仕事です!
よく「データサイエンティストは理系が多いですか?」と聞かれるのですが、実は妄想が好きな人に向いている仕事。文系の人は妄想するのが得意なので、データサイエンティストが向いているとも言えると思います!
課題を決め「こういうことを知りたい」という目的を決めたら、現状を把握するためのリサーチを行います。リサーチをもとに仮説を立て、仮説を立ててから初めてデータを集めるんです。データを闇雲に集めてはいけません。このプロセスがとても大事!
ホットケーキミックスのデータマーケティング
ではこのプロセスに則って、どのように仕事を進めているのか「ホットケーキミックス」のデータマーケティングを例に挙げて紹介します。
まずは予測を何割当てるかを決めます。次にホットケーキの市場について超絶調べます。たとえば「いつ売れるのか」「誰が買うのか」などですね。これらのリサーチをもとにパターンを読み解き、仮説を立てます。その上でどんなデータから予測するのかを考える……という流れです。
これらを進めるためには、市場について知っているビジネススキルと、データを見るサイエンススキル、データを集めるスキルなども必要となります。
ホットケーキの場合は夏は売れにくい傾向があります。なぜなら、暑いから。また毎年2月に売れる傾向があります。これはバレンタインの手作り需要だと考えられますよね。12月も売れていますが、これはクリスマスケーキの手作り需要でしょう。また2020年4月は極端に売れたというデータもあります。意外と忘れがちですが、コロナによる緊急事態宣言で巣ごもり需要が上がったからだと予測できます。
このように傾向をみて理由を考えるのにおすすめなのが、「空・雨・傘」というフレームワークです。
「空が曇っている(空)」という事実から「雨が降りそうだ(雨)」という解釈をし、「傘を持っていく(傘)」という行動を導き出すというもの。 考える力が問われるので、ぜひやってみてください!
演習2: 仮説検証のためのデータ分析計画を立案
ここからは再びデータをもとにしたグループワークを行うことになりました。
課題:化粧品サブスクサービスの退会の予測
先ほど分析した化粧品会社が2021年から行っている、サブスクサービスについての課題です。
このサブスクサービスは、最初は順調だったのですが1年で新規会員数が増えにくくなり、退会率が増加しています。今からお渡しするデータを元に「サブスクサービスの解約理由」の特定と「こういう施策が打てたらいいな」という解決策の計画を考えてみましょう!
提供されたデータは
- 売上高の推移
- 会員の性別・年代構成
- サブスク新規加入者数
- サブスク退会率
- 継続者のサブスク契約 認知の経由メディア
- 継続者のサブスク契約 解約理由
以上の6つ。これらのデータを元に、グループで分析を行いました。

アドバイスを受けながらグループ内で仮説を立て、解決策を検討。
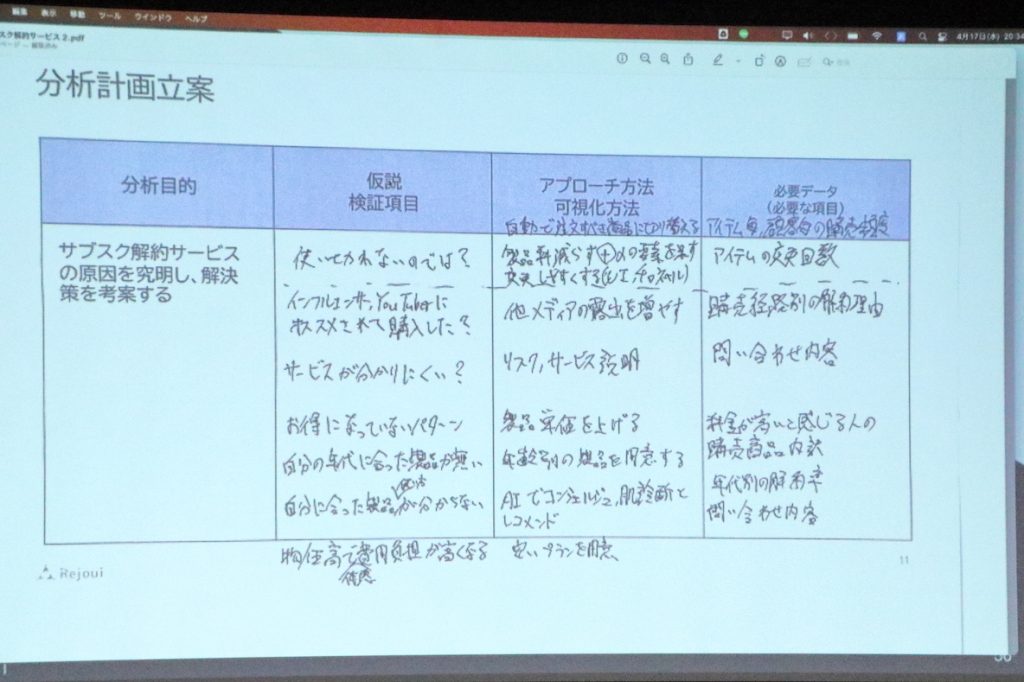
代表して1グループから発表をしていただきました。
やってみて、いかがだったでしょうか?
今やったような仮説を検証するためには、データを集めないといけません。ですが会社であれば、ある程度のデータを持っているはずです。
また数字としてのデータだけではなく、お客様からの声を聞くのは結構大事。定量的な調査と定性的な調査を行うのも重要です。たとえば細かなアンケートやインタビューなどですね。
これらは「MAツール」をはじめ、自動で行えるツールが多く出てきています。大体のものが一気通貫で全部やってくれるので、活用してみるといいですよ。ただし「どんなデータを使うか」はツールを使う上でも重要な判断です。今日の学びを活かしましょう!
今日のまとめ

では最後にまとめとして、データの力を解き放つのに必要な3つのポイントを紹介します。
1つ目が「課題背景に対する理解」。そのビジネスに詳しいかどうかという部分であり、対象の事柄に詳しくなければ、データを見ても気がつくことができません。
2つ目が「分析手法に対する理解」。現在はAIが発達していますが、AIが算出したものが正しいかどうかは人間が判断できなければいけないですよね。正しく見えて実は相応しくないことも多いので注意しましょう。
そして3つ目は「結果に対する判断力」。どんなビジネスでも、最終的な意思決定は人間の役割です!
データの力を最大限に使うための3つのポイント、ということで紹介しました。お話は以上です。ありがとうございました!
□まとめ
データ活用はただ数字と向き合うだけではないと、深く実感することができた今回のワークショップ。
データを闇雲に集めるのではなくリサーチを徹底的に行い、仮説を立て、それを検証するためにデータを集めるという実践的な流れの一端を体験することができた濃密なワークショップでした。
E CROSS PARKでは、今後もさまざまなテーマのワークショップを開催予定です。
ぜひみなさまのご参加をお待ちしております!
次回のレポートもお楽しみに!
CATEGORY
TAG CLOUD



-

【E CROSS TALK REPORTS vol.06】
ビジネスパーソン必見!提案書作成に必要な
ストーリー/スライドの技術 -

【E CROSS TALK REPORTS vol.02】
未経験からWEB業界に通用する人材になるために
〜採用担当から見た求められる人物像とは〜 -

【E CROSS TALK REPORTS vol.03】
WEBプロジェクト成功のカギはココにある!プロジェクトマネージャの役割とスキル解説 -

【E CROSS TALK REPORTS vol.05】
ゼロからはじめるAWS
Web業界なら知っておきたいサーバー・ネットワーク入門 -

【E CROSS TALK REPORTS vol.01】
未経験からWEB業界に通用する人材になるために
〜業界のイマとミライを語る〜







